Los "big data" son solo un primer indicio de un cambio histórico radical en el modo de adquirir nuevos conocimientos.
Todos nuestros dispositivos conectados están alimentando un gigantesco crecimiento de datos, algo completamente nuevo en la historia. En los últimos 3 años, hemos generado más datos que en los anteriores 199.997 años de la historia humana. Ésto significa que la forma en que pensamos acerca de los datos y de la tecnología tiene que cambiar en el nivel más fundamental. No es sólo una cuestión de escala: los tipos de datos y la forma en que pueden afectar a la vida humana y el mundo son diferentes en su mismo núcleo.
Los enfoques tradicionales ya no van a funcionar con estas grandes cantidades de datos; no van a producir resultados relevantes en un mundo donde la información en tiempo real provendrá de dispositivos conectados presentes en todo, desde los latidos del corazón humano a los datos interestelares fluyendo constantemente y a un ritmo creciente.
Ahora todo el mundo tiene acceso a la información, y la tecnología y las herramientas necesarias para extraer valor de esta explosión de datos están en desarrollo y se promete que estarán progresivamente a disposición de una mayor cantidad de gente.
No se trata solamente de los llamados "big data", acumulados por las redes sociales para conocer mejor a sus usuarios y programar la publicidad, lo que también realizan las empresas para tomar mejores decisiones tanto en el plano del mercadeo como en la gestión de su producción. Los medios de comunicación se preguntan cómo utilizar mejor la cantidad de datos de todo tipo que entregan los gobiernos y que encuentran en la misma WWW. Por ahora, hacerlo no es fácil. Se requiere dominar la llamada nueva "ciencia de datos", y nuevas herramientas de análisis, desde el lenguaje R hasta las plataformas Hadoop o Spark. El nuevo rol del ingeniero o científico de datos está evolucionando y tanto las habilidades como los conocimientos requeridos están fluctuando junto con las tecnologías como el aprendizaje de máquina y la computación distribuida. Cada nueva función descubierta tiene su propia exigencia de competencias y no hay aún "modelo estándar" (si es que llega a haberlo alguna vez).
Lo que de todos modos se desprende ya de la transformación en marcha es, por una parte, su necesidad y, por otra, la necesidad de reemplazar las matemáticas y las estadísticas tradicionales por la idea de matemáticas borrosas (probabilidad) y conjuntos difusos. Cambiar el enfoque y la metodología es indispensable debido a la masividad de los datos que ya empezó a generar la "internet de las cosas". Ya no es posible conocer realmente el mundo de hoy sin analizar enormes conjuntos de datos. Sistemas avanzados de análisis, capaces de operar sin hipótesis previas y de generar pronósticos o recomendaciones serán indispensables para que tales datos sean realmente útiles, tanto en empresas de todo tamaño como -especialmente- en los gobiernos. La única vía posible que se visualiza por ahora es la del "aprendizaje de máquina", una forma de inteligencia artificial que permite a los computadores más poderosos extraer de estas masas de datos conocimientos aprovechables.
Por ahora se requieren para ello máquinas poderosas (supercomputadores) o conjuntos de computadores (clusters) que se repartan las tareas. Facebook, Google, Yahoo, Twitter y otros utilizan estos equipos e invierten en desarrollos de inteligencia artificial para utilizar la información que les llega a raudales. Netflix está cambiando el panorama de la televisión no solo por su modelo de distribución sino también por su toma de deciciones en cuanto a su programación y sus ofertas personalizadas, basadas en el análisis de datos, en que ha pasado de un análisis tradicional a uno basado en los recursos más modernos del momento que se ilustran en el siguiente cuadro (de una presentación de Blake Irvine recogida en DZone):

Y múltiples empresas ofrecen este tipo de servicio en su nube: IBM, Microsoft, Amazon... Pero hemos de recordar la Ley de Moore, que ha asertado en asegurar que el poder de los computadores se duplica cada dos años, así que hay esperanza para el mejoramiento tanto de las aplicaciones como de los equipos para los investigadores y, algún día, para todos. El conocido software de análisis estadístico de SAS ya se hizo cargo de las nuevas tendencias y anunció su "Factory Miner", capaz de "automatizar el proceso de construcción de modelos predictivos" a partir de cualquier conjunto de datos en formato de tabla y con algoritmos de aprendizaje de máquina.

Todas las grandes empresas se hacen preguntas hoy acerca de este nuevo panorama, si no han adoptado ya la nueva tendencia. pronto no les será posible defender sus negocios sin este tipo de herramienta. Pero, por ahora, se encuentran con un verdadero caos de recursos, incluso en el marco de la plataforma más genérica y comunmente utilizada que es Hadoop, como se muestra en el siguiente gráfico (preparado por MapR):
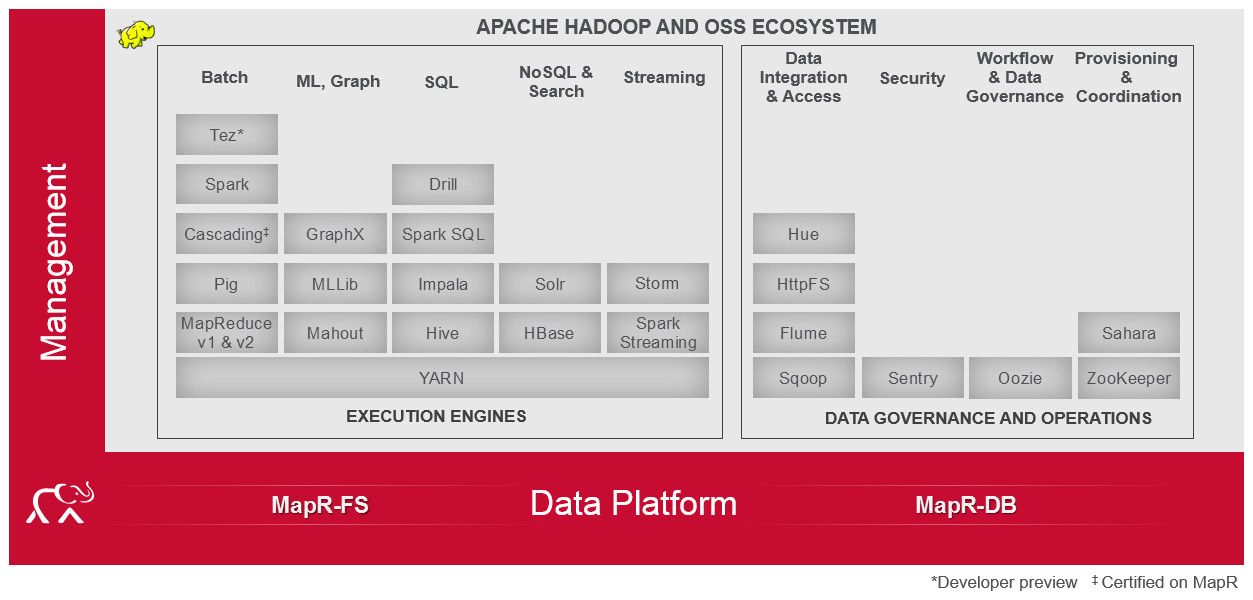
Sin duda, el software seguirá evolucionando y esperemos que sea en una línea de mayor integración (como ha ocurrido hace años con la ofimática) y con alternativas más compactas que sean útiles para las PYMES, los investigadores-académicos y cada personas deseosa de explorar el nuevo mundo de los datos (y no solo para los más poderosos). Avanzar en estas nuevas tecnologías y ponerlas a disposición de todos es un real imperativo social.
- "Con el tiempo, vamos a mirar atrás y ver este año, 2015, como el año en que hicimos un cambio fundamental en nuestra forma de pensar, de descubrir simplemente ideas a aplicarlas a gran escala y en formas que producirán ideas que no podemos imaginar en este momento." nos dice Joel S. Horwitz, Director de Analytics de IBM en la revista de tecnología del MIT. Llevará a la "economía de la perspicacia" (insight economy).
La ciencia de datos, sin embargo aún debe evolucionar. Utilizar ciegamente el aprendizaje de máquina para el análisis de Big Data y, con ello, tomar decisiones basadas en predicciones artificiales como se está haciendo ahora podría ser muy riesgoso. Las empresas que ofrecen estos sistemas o los servicios asociados nos piden que confiemos ciegamente en los algoritmos creados por sus ingenieros pero no nos dan, hoy, ninguna prueba de que son realmente confiables y no nos permiten, lamentablemente, comprender los resultados que entregan.
IBM ha intentando paliar este problema con "Watson Paths", que ofrece una visualización del árbol de decisión seguido por este supercomputador. Pero el experto en IA, Danny Hillis, comenta en el mismo artículo que no es suficiente (requiere aún una interpretación) y que la única solución satisfactoria sería producir un relato ("story telling") describiendo cómo se llega a la conclusión ofrecida. Exponer el razonamiento facilita la comprensión, la aceptación (o refutación) y el aprendizaje humano. ¿Qué pasaría si un gobierno tomase decisiones de política social o en las "ciudades inteligentes" basado en algoritmos erróneos? ¡Peor aún si un médico decide un tratamiento basado en un diagnóstico erróneo, por confiar en un programa de IA! Steve Lohr (The New York Times, 7/04/2015) indica un camino que la "ciencia de datos" debe recorrer a toda costa antes de ser realmente confiable: "Estas preguntas están estimulando una rama de estudio académico conocida como rendición de cuentas algorítmica (algorithmic accountability)".
(Más comentarios del artículo de Lohr en ComputerWorld, 19/06/2015)
Fuentes: MIT Technology Reviews, 15/06/2015.
DZone, 16/06/2015.
Computerworld, 18/06/2015.
ComputerWorld, 19/06/2015.
Nota: El post de la semana pasado ha sido revisado.
No hay comentarios:
Publicar un comentario
Nota: solo los miembros de este blog pueden publicar comentarios.